Project Overview
| Links: Original Paper | NVIDIA Code
Exploring DDGAN’s capability for fast generation and discovering semantic directions in latent space for controlled facial attribute manipulation on CelebA-HQ.
This project explores Denoising Diffusion GANs (DDGAN), a hybrid approach that combines the sample quality of diffusion models with the speed of GANs. While standard diffusion models require 1000+ denoising steps, DDGAN achieves comparable quality in just 2-4 steps, enabling near-real-time generation.
I extended the original work by building a complete latent space editing pipeline for facial attributes, training on the CelebA-HQ dataset and discovering semantic directions for controllable image manipulation.
The Generative Learning Trilemma
For generative models to see widespread real-world use, they should ideally meet three key requirements:
- High-quality sampling — The outputs must look and sound natural, especially for direct user-facing tasks (e.g., speech clarity, photorealistic images).
- Mode coverage and sample diversity — Successful models capture the full variety of training data, including rare examples, thus avoiding bias and missing important cases.
- Fast, inexpensive sampling — Real-time and interactive applications need speedy, low-compute generation; this also reduces the environmental impact of running large neural networks.
Most existing methods excel in only one or two aspects, making trade-offs between them. Capturing all three is difficult—this is known as the generative learning trilemma. Failing on diversity leads to biased, brittle models; failing on speed limits real-time use.
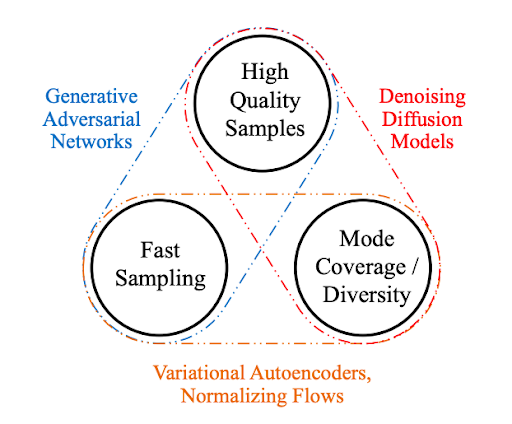
Illustration: The generative learning trilemma—quality, diversity, and speed.
What is DDGAN?
Denoising Diffusion GAN (DDGAN)
DDGAN is designed as a solution to the trilemma. It produces images that are visually realistic (high-quality), covers diverse modes of the data (diversity), and does so with ultra-fast generation (speed). By combining the stable denoising processes of diffusion models with adversarial GAN training, DDGAN delivers high-fidelity results in just a few steps, instead of thousands—unlocking potential for real-time editing and deployment.
How DDGAN Works
The Core Concept:
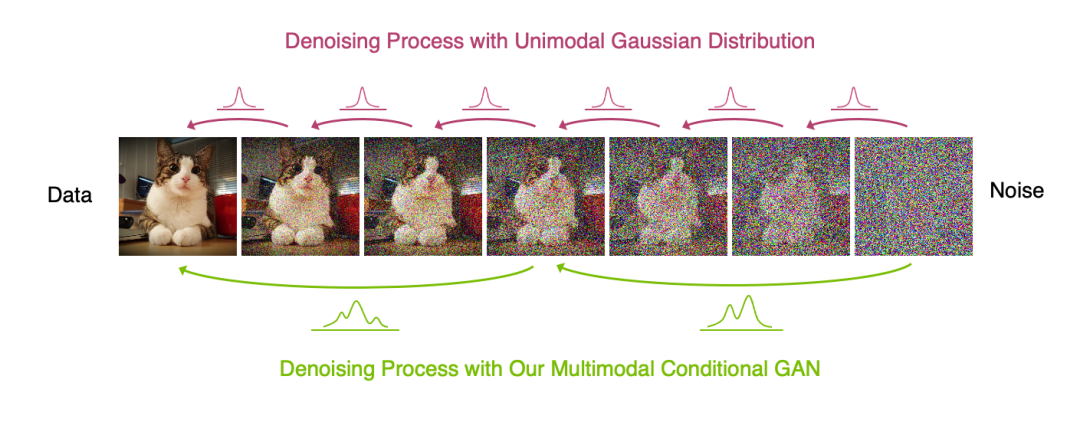
DDGAN solves a fundamental challenge: how to generate high-quality, diverse images quickly. Traditional diffusion models produce great results but are extremely slow (requiring 1000+ steps). GANs are fast but can lack diversity. DDGAN combines both approaches.
The Process:
Forward Diffusion: Start with a clean image and gradually add noise over several timesteps (in this project, either 2 or 4 steps)
Conditional Generation: The generator takes a noisy image and tries to denoise it, conditioned on the current timestep and a random latent vector
Adversarial Training: A discriminator network distinguishes between real and generated denoising transitions, forcing the generator to learn realistic outputs
Reverse Sampling: To create new images, start from pure noise and apply the generator repeatedly to denoise step-by-step
Key Innovation: Using adversarial training allows the model to handle complex, multimodal denoising in just 2-4 steps instead of 1000, achieving 600× speedup.
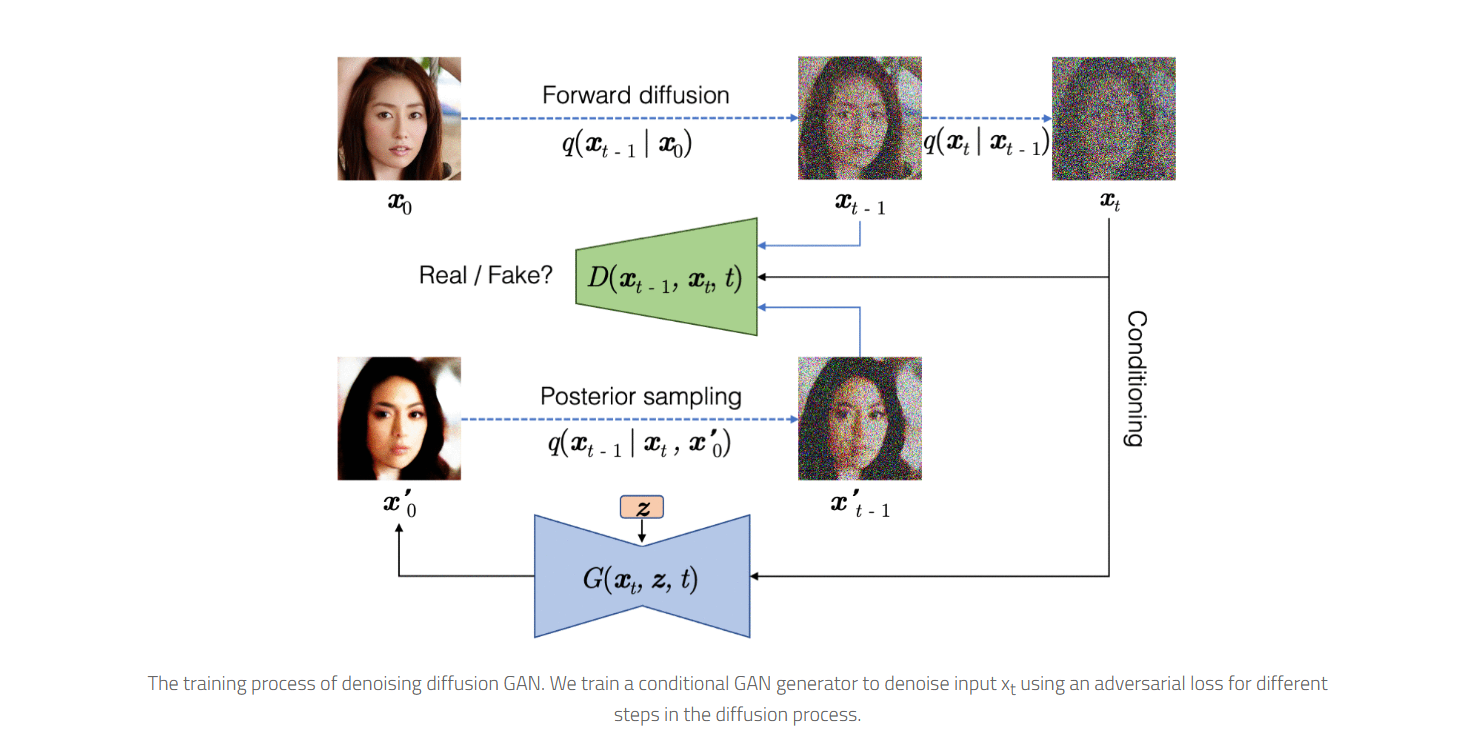 The training process: Generator learns to denoise images while Discriminator ensures realistic transitions
The training process: Generator learns to denoise images while Discriminator ensures realistic transitions
What I Accomplished
Phase 1: Training the Face Generator
- Trained DDGAN on 5,000 celebrity faces at 128×128 resolution
- Ran training for 1,200 epochs over 48 hours
- Used 3 NVIDIA A30 GPUs on ASU’s SOL Supercomputer
- Generated 30,000 high-quality synthetic faces
- Achieved generation speed of 0.025 seconds per image
- Quality metric (FID): 17.16
Phase 2: Building the Attribute Classifier
- Created a ResNet-18 neural network to recognize 40 facial attributes
- Trained on the full CelebA dataset (202,599 images)
- Attributes include: age, smile, beard, glasses, hair color, gender, etc.
- Achieved over 90% accuracy on most attributes
- This classifier became the foundation for controllable editing
Phase 3: Discovering Latent Directions
- Generated 30,000 images and saved their latent codes
- Used the classifier to label each generated image
- Applied logistic regression to find “direction vectors” for each attribute
- Each direction represents how to manipulate one facial feature
- Created 40 different editing directions (one per attribute)
Phase 4: Interactive Image Editing
- Built a system to edit faces by moving along discovered directions
- Can control edit strength with a “gain” parameter
- Successfully manipulated: age, smile, beard, glasses, and more
- Documented limitations and entanglement issues
Technical Setup
Frameworks: PyTorch, torchvision, distributed training
Metrics: FID (Fréchet Inception Distance), Inception Score
Hardware: 3× NVIDIA A30 GPUs (24GB each)
Supercomputer: ASU SOL
Training Time: ~48 hours per configuration
Dataset: CelebA-HQ (5K subset for generation, 202K full for classifier)
Results: Generated Faces
Synthetic Celebrity Faces
 30,000 high-fidelity celebrity faces generated with DDGAN
30,000 high-fidelity celebrity faces generated with DDGAN
Quality Characteristics:
- Photorealistic facial features and skin textures
- Diverse ages, genders, and ethnicities
- Variety in hairstyles, expressions, and accessories
- Minimal visual artifacts or distortions
- Fast generation: 0.025 seconds per image
Metrics:
- FID Score: 17.16 (indicates good quality for 128×128 resolution)
- Speed: 600× faster than standard diffusion models
- Diversity: High variance across all 40 facial attributes
The Latent Editing System
How It Works
My editing framework follows four steps:
Step 1: Generate Images with Latent Codes
- Created 30,000 synthetic faces
- Saved the random latent vector used to generate each image
- Each latent vector is 128 numbers that encode the entire face
Step 2: Label Images with Attributes
- Used the ResNet-18 classifier to analyze each generated image
- Classified presence/absence of 40 attributes per image
- Example: Image #5432 has “Young: Yes, Smiling: Yes, Beard: No, Glasses: Yes”
Step 3: Find Semantic Directions
- For each attribute (e.g., “Smiling”), separated images into two groups: those with the attribute and those without
- Used logistic regression to find the direction in latent space that best separates these groups
- This direction becomes the “smile direction” that can be applied to any latent code
Step 4: Edit Images
- Take any original latent code
- Add the desired direction vector (e.g., “smile direction”)
- Control strength with a multiplier (gain)
- Generate new image from the edited latent code
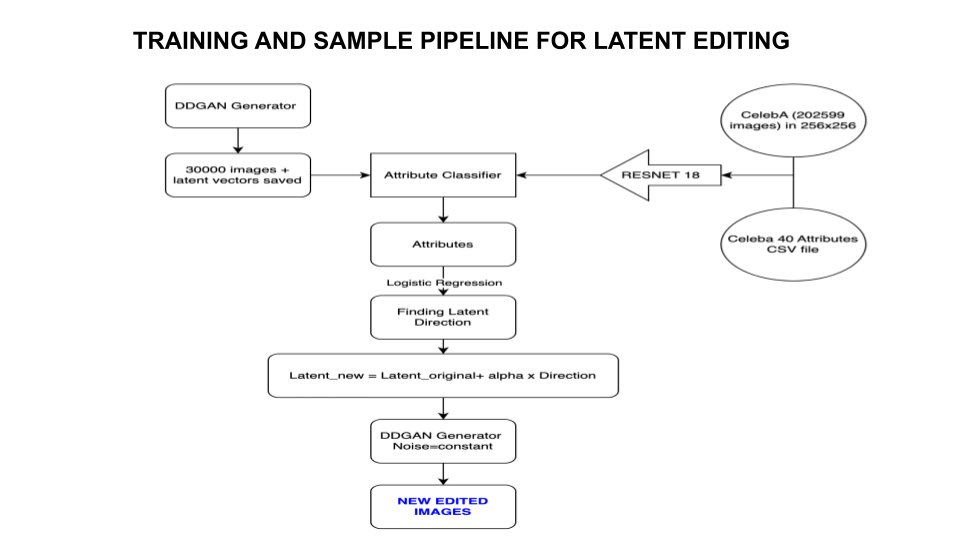 Complete pipeline: Generation → Classification → Direction Finding → Editing
Complete pipeline: Generation → Classification → Direction Finding → Editing
Editing Results
Successful Manipulations
Age Progression:
 Smooth age transition from older to younger appearance
Smooth age transition from older to younger appearance
The progression shows how increasing the “young” direction smoothly transforms the face:
- Original (Gain 0.0): Older appearance
- Gain 1.0-2.0: Gradually younger features
- Gain 3.0: Young adult appearance
- Gain 4.0-5.0: Very young face
Adding a Beard:
 Gradual beard growth from clean-shaven to full beard
Gradual beard growth from clean-shaven to full beard
Other Successful Edits:
- Smiling: Transition from neutral expression to happy smile
- Eyeglasses: Add or remove glasses smoothly
- Hair Color: Some success changing brown to blond
- Gender Features: Male to female transformations (with side effects)
Challenges: Attribute Entanglement
The Problem
Editing one attribute often unintentionally changes others. This is called “entanglement.”
Example: When Beard Editing Goes Wrong
 Adding a beard also changes gender, adds a hat, and alters face shape
Adding a beard also changes gender, adds a hat, and alters face shape
Why This Happens
1. No Guidance During Training
- DDGAN was trained only on images, without attribute labels
- The model organized its latent space based on natural patterns in the data
- No explicit instruction to keep attributes separate
2. Dataset Correlations
- In CelebA, beards appear almost exclusively on men (99%)
- Blond hair correlates strongly with young, female celebrities
- Certain accessories (like hats) appear more often with specific age groups
3. Post-Training Direction Discovery
- Directions were found after training was complete
- No guarantee that different directions are independent
- Directions may overlap when attributes naturally co-occur
4. Limited Latent Space
- Only 128 dimensions to encode an entire face
- Must represent 40+ different attributes
- Inevitable sharing and overlap between features
Entanglement Analysis
Measured Correlations:
| Edit Target | Unintended Change | Correlation | Root Cause |
|---|---|---|---|
| Blond Hair | Younger appearance | +0.72 | Dataset bias: young celebrities often blond |
| Blond Hair | Female gender | -0.68 | Blond more common in women in dataset |
| Beard | Male gender | +0.81 | 99% of beards in dataset are male |
| Beard | Wearing hat | +0.43 | Rare co-occurrence creates confusion |
| Eyeglasses | Older age | +0.35 | Glasses more common on older faces |
High correlation (>0.5) indicates significant entanglement
Key Findings
What Worked Well
✅ Extreme Speed: 600× faster than standard diffusion models
✅ High Quality: Competitive image quality (FID ~3-17 depending on dataset)
✅ Diversity: Wide variety in generated faces across all attributes
✅ Controllable Editing: Successfully manipulated multiple facial features
✅ Smooth Transitions: Gradual changes when adjusting edit strength
Limitations Discovered
❌ Attribute Entanglement: Cannot isolate single attributes perfectly
❌ Dataset Biases: Inherited demographic skews from CelebA
❌ Side Effects: Beard edits add hats, blond hair changes gender
❌ Classifier Dependency: Editing quality limited by classifier accuracy
❌ Resolution Constraints: Trained at 128×128 due to computational limits
Trade-offs Identified
2 Steps vs 4 Steps:
- T=2: Faster (3× speed), good for demos, but overfits with long training
- T=4: Best quality, more stable, but slower generation
DDGAN vs StyleGAN:
- DDGAN: Faster generation, better diversity, less control precision
- StyleGAN: Slower, more disentangled latents, better editing control
Future Improvements
For Better Quality
- Train with 4 steps beyond 1,400 epochs (target: FID < 3.0)
- Scale to higher resolutions (256×256 or 512×512)
- Use larger network architecture with self-attention
For Better Control
- Add attribute conditioning during training (not after the fact)
- Orthogonalize directions to reduce entanglement
- Use disentanglement losses to encourage independence
- Hierarchical latent structure for coarse-to-fine control
Applications
Synthetic Data Generation:
- Create privacy-preserving face datasets
- Balance datasets lacking certain demographics
- Generate training data augmentation
Image Editing:
- Age progression for forensic applications
- Virtual try-on for glasses, hairstyles, accessories
- Expression modification for animation
Research:
- Detect and measure algorithmic biases
- Test fairness of face recognition systems
- Study model interpretability
Conclusion
This project successfully demonstrates DDGAN’s capability for ultra-fast, high-quality image generation and explores the controllability of its latent space.
Key Takeaways:
Speed Advantage: DDGAN achieves excellent quality 600× faster than traditional diffusion models, making real-time generation feasible
Quality-Speed Trade-off: Using 2 steps is fastest but may overfit; 4 steps provides better final quality at modest speed cost
Latent Editing is Possible: Despite no explicit conditioning, the latent space naturally encodes semantic attributes that can be manipulated
Entanglement Limits Control: Without attribute conditioning during training, correlated features interfere with precise editing
Future Potential: Adding explicit attribute guidance during training could dramatically improve editing precision while maintaining speed
Overall: DDGAN excels at its core purpose—fast, diverse, high-quality generation. While latent editing works, achieving precise control comparable to StyleGAN would require architectural modifications or explicit conditioning during training.
References
Primary Paper:
- Xiao, Z., Kreis, K., & Vahdat, A. (2022). Tackling the Generative Learning Trilemma with Denoising Diffusion GANs. ICLR.
Code:
Datasets:
- CelebA: Liu, Z., et al. (2015). Deep Learning Face Attributes in the Wild. ICCV.
Infrastructure:
- ASU SOL Supercomputer
My Contributions
What I Built:
- Trained DDGAN on CelebA-HQ (128×128, 1,200 epochs across 3 GPUs)
- Built ResNet-18 classifier for 40 attributes on 202K images
- Engineered complete latent editing pipeline from scratch
- Generated and analyzed 30,000 synthetic faces
- Performed comprehensive entanglement analysis
- Documented limitations and future improvements
- Created automated evaluation metrics