AI‑Accelerated Multi‑Modal Tutor
| Links: GitHub | Demo Video
LLM+RAG tutor with PDFs/videos, CPU→GPU conversion, and benchmarks on NVIDIA A100.
This project builds a multi‑modal AI tutor that ingests PDFs and videos, performs RAG‑based Q&A, and auto‑converts CPU code to GPU for speedups — benchmarking on NVIDIA A100.
The pipeline combines vector retrieval, LLM reasoning, and GPU acceleration (CUDA / RAPIDS / Spark+GPU) to keep responses fast and scalable.
Stack: Gradio UI · LangGraph orchestration · FAISS/Chroma vector DB · Whisper (ASR) · PyTorch/CuPy · (NVIDIA) GPU‑accelerated Spark/CUDA kernels.
What’s AI‑Accelerated here?
- CPU → GPU conversion for the heavy parts (embedding, retrieval ops, and batched inference where possible).
- RAPIDS / Spark on GPU patterns for data prep + feature wrangling.
- A100 benchmarking for end‑to‑end latency (ingest → retrieve → answer).
Gallery
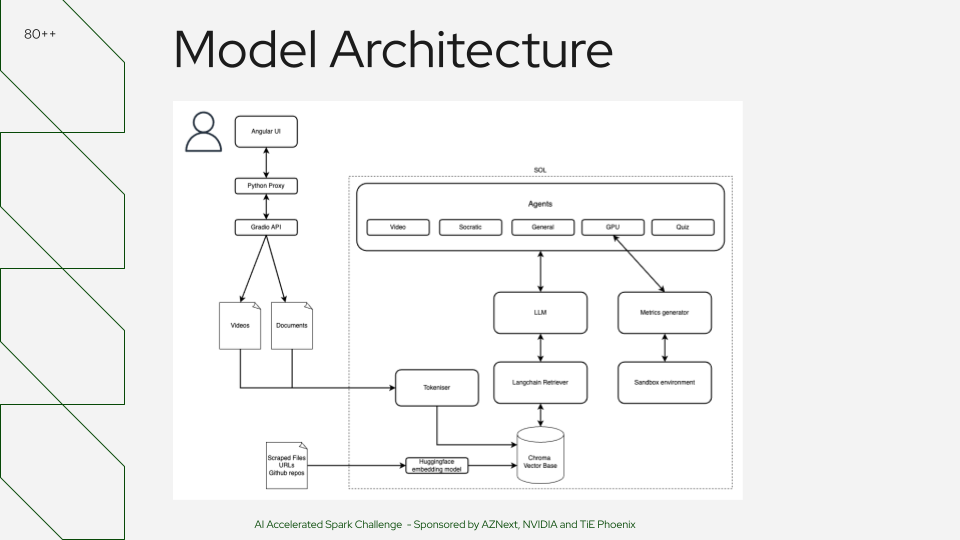 High‑level pipeline: ingestion → chunking/embedding → vector store → query routing → GPU‑accelerated retrieve+rerank → answer generation.
High‑level pipeline: ingestion → chunking/embedding → vector store → query routing → GPU‑accelerated retrieve+rerank → answer generation.
Demo Video
Details
Ingestion
- PDFs → chunked (semantic/page), embedded (GPU when available), stored in FAISS/Chroma.
- Videos → transcribed via Whisper, segmented, embedded, merged into the same vector space for cross‑modal retrieval.
Retrieval + Reasoning
- Hybrid retrieval (semantic + keyword) with rerank for relevance.
- LangGraph orchestrates tools (retriever, summarizer, code executor).
- Grounded answers with citations and follow‑ups.
GPU Acceleration
- Vector ops and batch inference offloaded to GPU (A100).
- Spark on GPU / RAPIDS patterns for preprocessing large corpora (from the linked repo).
- CuPy / PyTorch for custom kernels where needed.
Benchmarks
- Report latency per stage (ingest, retrieve, generate) on CPU vs GPU.
- Batch sizes and sequence lengths documented with hardware notes (A100, driver/CUDA version).